This started like most dumb startup ideas: two ex-MBB consultants and a pitch deck.
As part of my Master's in AI, I joined a capstone project with an industry sponsor that came with an enticing premise: use AI to solve the global infrastructure funding gap.
Here's how they framed it: there's a mountain of money — about $340 billion — sitting in the coffers of institutional investors, looking for "impact."
Meanwhile, infrastructure projects in emerging markets — roads, bridges, solar plants — can't raise the capital to get off the ground.
Our project sponsors believed this was a visibility issue. Investors just couldn't see the projects. And like all good consultants, they had a solution:
Build a marketplace that leverages AI to match capital with projects.
The whole pitch reeked Big Davos Energy.
They came loaded with documents from $2.5B worth of Latin American infrastructure projects. Real ones, with actual numbers and feasibility studies.
They envisioned a platform where investors could browse through these opportunities like Zillow listings, with AI doing the matchmaking. (Unlike Zillow, we'd theoretically recommend projects you could actually afford.)
But something smelled off.
If investors were really desperate for deal flow, why hadn't they solved it? These firms have global reach, billion-dollar funds, and more resources than the Swiss government. They're not exactly waiting for startups to slide into their DMs with Peruvian wind farms.
And then there was the "AI" part. What they were calling AI looked more like an if-this-then-that filter. The tech wasn't doing anything investors couldn't do themselves with a couple drop-downs and a decent Excel sheet. Built for courting VCs, not solving real problems.
So I convinced the team to pause. We hadn't talked to a single investor. Not one developer. We were about to build a product based on vibes and PowerPoint.
Maybe we should, you know, check if the problem actually existed.
Real talk with real people
Getting to those conversations was its own mess.
We started by cold-emailing over 50 people, framing it like a startup. These people either ignored us or politely told us to f off.
Then we reframed it as a capstone project for school and suddenly people were eager to help.
I guess 'student project' signals learning. 'Startup' signals you're about to sell them something.
I ran structured problem-market fit interviews with 15 people across the deal chain, probing their workflows, jobs-to-be-done, and testing our assumptions about whether this was really a visibility/discovery problem:
- Infra investors
- Project developers
- Blended finance veterans
The pattern was obvious. Everyone said the same thing:
"Matching isn't the problem. Screening is hell." — Private Infra Fund, NYC
"We passed on decent projects because we didn't have time to read them." — DFI advisor
"Screening each project takes weeks, and our analysts have to do all this grunt work." — PE partner, NYC
So yeah — visibility wasn't the bottleneck.
It was time and trust.
What we built
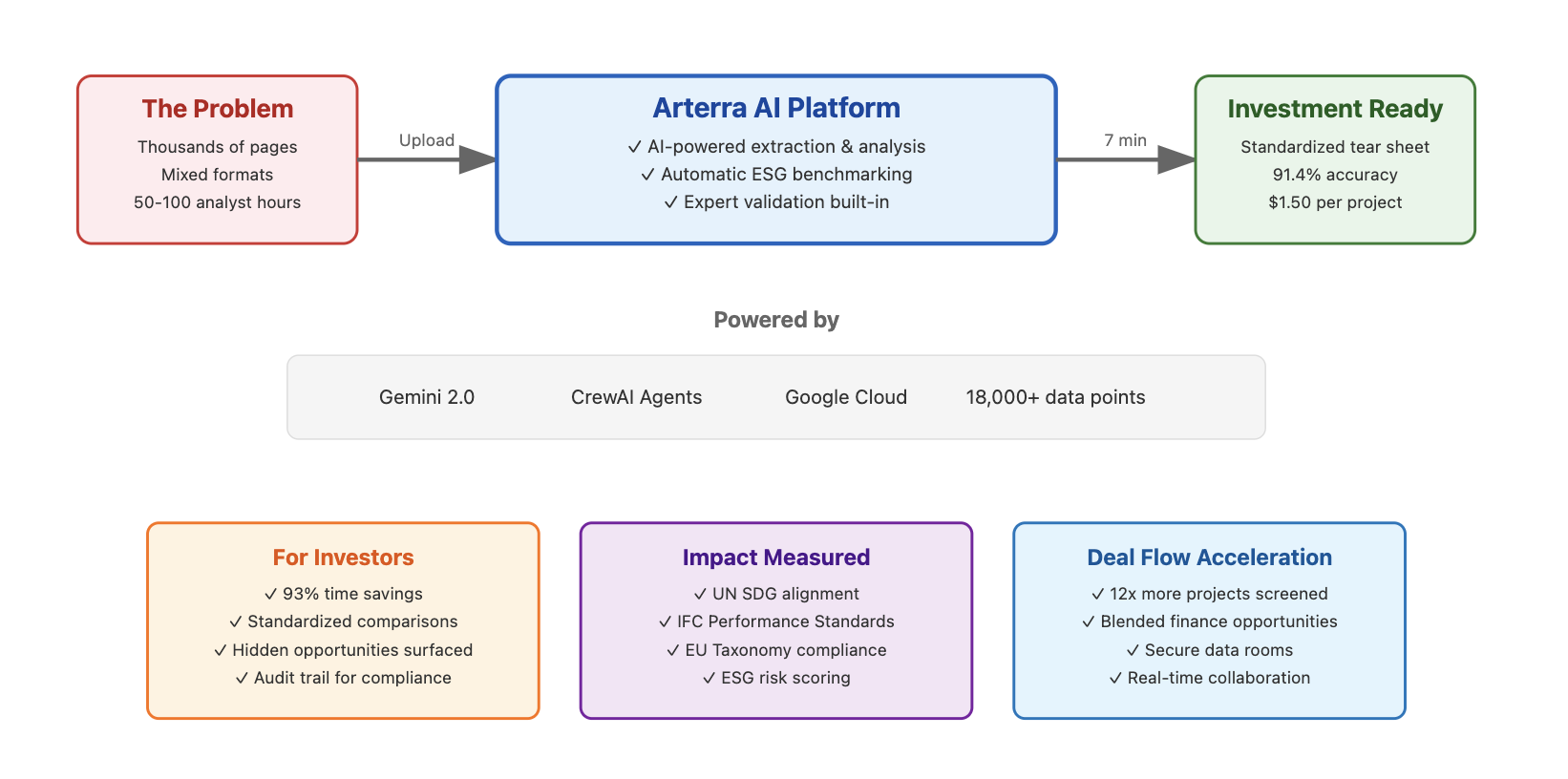
Once we understood the real problem — analysts spending days manually reviewing messy documents just to figure out if a project was worth the partners' time — the solution became obvious.
We built infrastructure for screening infrastructure.
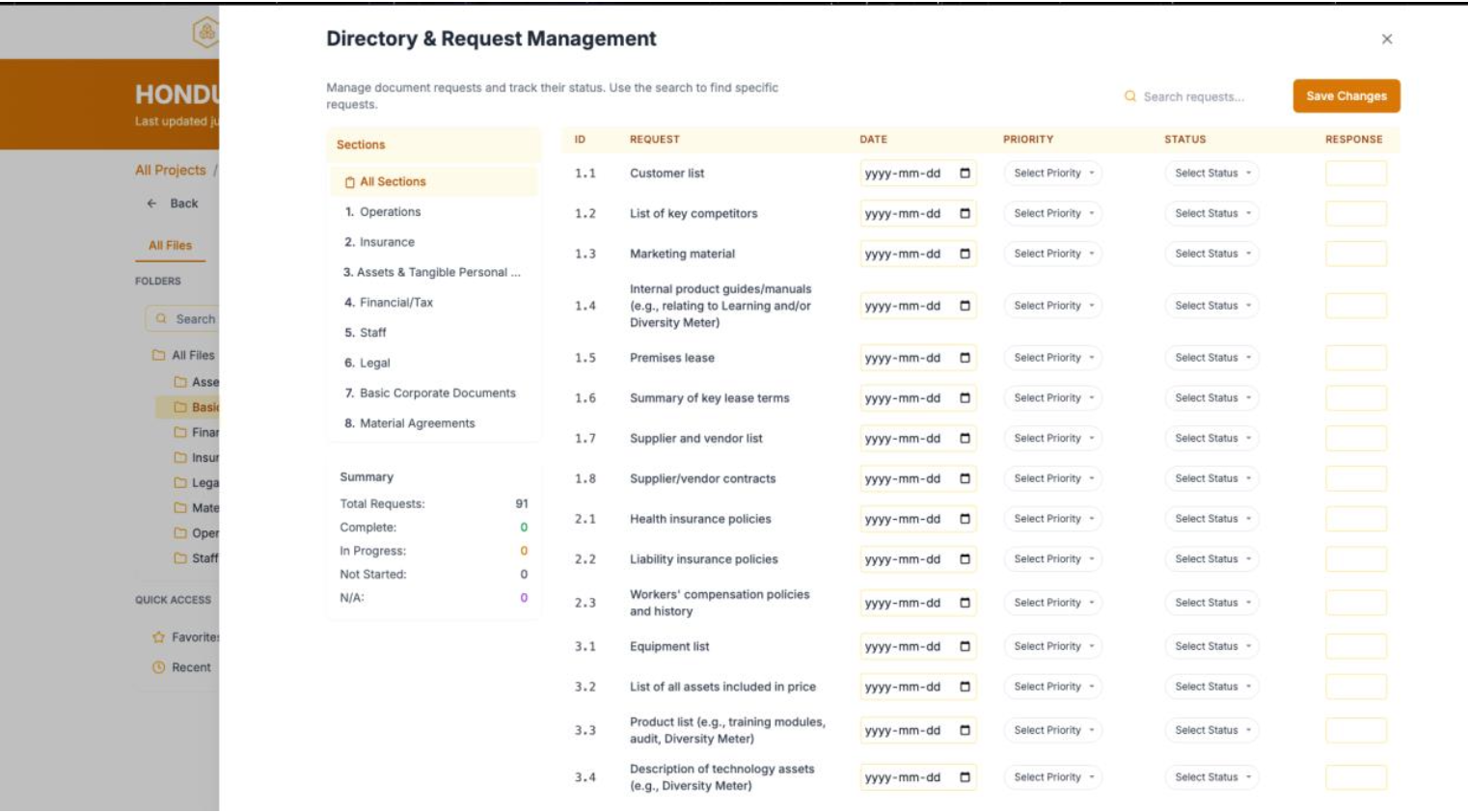
Dump in feasibility studies, financial models, scanned municipal approvals — all the stuff that turned NYC into a booming therapy market. The system extracts what matters, benchmarks it against real comparables and frameworks, and spits out a clean tear sheet.
Every project gets the same treatment, the same format, the same scrutiny.
To hedge against LLMs' favorite hobby (making shit up), every output got validated. No negative IRRs, no mixed-up units, no made-up numbers where data was missing. When the agents weren't sure, they turned themselves in for human review.
What we had to kill
We killed plenty of features that sounded brilliant until users heard them.
| Feature | Cause of death |
|---|---|
| GenAI deal summaries | Investors hated it. "We don't want your bot's opinion on our deals. Just give us clean data." |
| Investor-side CRM tooling | Not a painkiller — out of scope for MVP |
| V1 dashboard | Overwhelmed users — too much raw JSON, not enough clarity |
| Matching deals to investors | Matching wasn't the problem, vetting was |
| End-to-end sourcing automation | Investors already have sourcing teams |
| Smart ESG scoring models | Distrusted unless fully explainable + auditable |
| Marketplace features | No liquidity without investor demand |
What broke along the way
The first time we ran real project files through our OCR pipeline, it choked so hard we thought it crashed. Camelot garbled tables, Gemini hallucinated headers, and our multilingual PDF processor just gave up. Two weeks and three fallback layers later, we had something that worked.
Then reality hit.
An ex-partner at a major PE fund laughed when we explained our open upload model:
"You really think developers are just going to hand their financial models to some random startup?"
That one sentence killed our entire architecture. We rebuilt the whole thing with gated access and zero-trust encryption, and pretended that was the plan all along.
We put it in the wild
Look, I spent half this story dunking on consultants, but here's the truth: without our sponsors, none of this happens. They brought real project documents to jump start the whole thing, opened real doors, and sold the hell out of this 'school project' to people with real money.
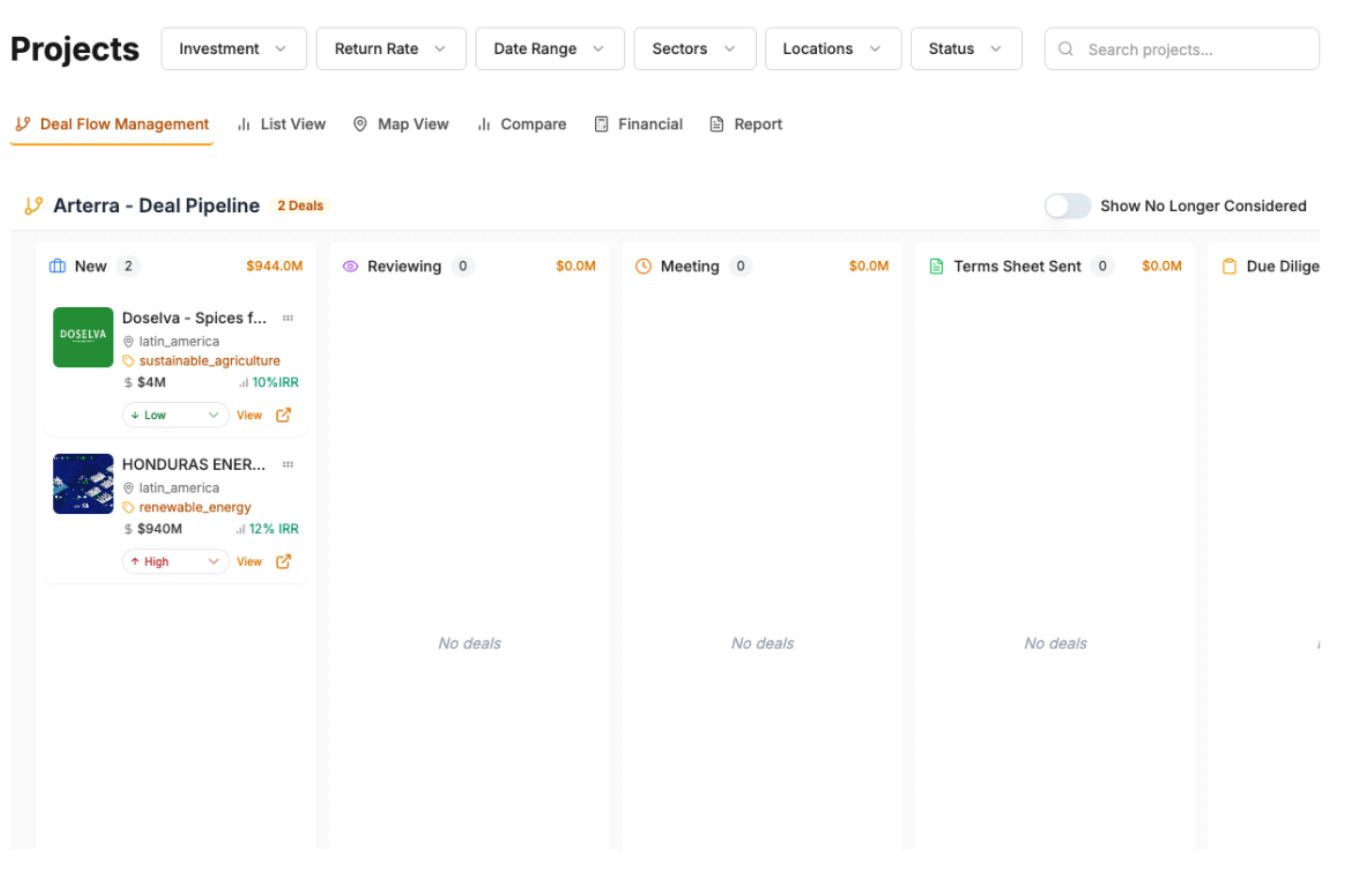
We ran a two-month pilot with a major Canadian public infra fund and some friendly investors. 25 real projects, real stakes — no cherry-picking.
| Metric | Before | After Arterra | Impact |
|---|---|---|---|
| Screening time | 60–100 hrs | ~7 min | >99% faster |
| Projects per analyst / month | 8–12 | 150+ | 12× lift |
| Accuracy | — | 91.4% | Validated by SMEs |
| Cost per screen | — | $1.50 | ~$3K saved per deal |
| NPS (pilot) | — | +62 | Both sides loved it |
One shelved project got a $220M term sheet mid-pilot because we freed up three analysts.
But let's not kid ourselves — this was early innings with friendly users and low-hanging fruit. The moment someone uploads 300MB of GIS data on hotel Wi-Fi, we'll see how robust this really is.
The bigger vision? Own the entire deal lifecycle from first look to post-close monitoring. But scaling from friendly pilots to hostile markets is where things get real.
The business reality check
Let me be straight: the product worked, but building any defensible product post-ChatGPT is a different game. We happened to be playing it in infrastructure, where the incumbents have every advantage except imagination.
The competition
Sure, there's InfraShares trying to be "Robinhood for roads" and Preqin selling league tables. But our real threats are more boring and more dangerous:
Intralinks adds one feature. They already own the data room market. One sprint team, one quarter, and they could ship "AI screening" as a checkbox feature. We'd go from "revolutionary" to "also included" overnight.
IFC builds it in-house. They have 200 engineers and infinite patience. Once we've proven the model works, what stops them from just… building it?
The Big 4 acquire something adjacent. They have the relationships, the trust, and the compliance badges. One acquisition of any doc-parsing startup and they're in our space with 10x our distribution.
Why our unit economics are both great and terrible
The numbers look amazing on paper:
- Our cost: $1.50 per screen
- Manual cost: $3–5K
- Pricing potential: $50–150K/year enterprise deals
But here's what the spreadsheet doesn't show:
- CAC could easily hit $50–75K. DFI sales means 6–9 month cycles, multiple trips to DC/Geneva/Singapore, pilot support, and deals that die in procurement after months of work.
- Payback periods stretch over a year. Even at $150K ACV, you're underwater until renewal.
- Churn risk is real. Annual contracts mean annual "do we need this?" conversations, often with entirely new stakeholders.
We're betting we can sign enough enterprises before Intralinks ships a feature or developers realize ChatGPT + Camelot gets them 80% there.
What actually might work
Despite all this, there's a path. Not a unicorn path, but a real business path:
- The market is massive and moves slowly. $3.3T in annual infrastructure funding. Even crumbs are meaningful.
- The pain is real. We didn't invent the 100-hour screening problem. Every investor we talked to had analyst burnout stories.
- Trust matters more than tech. In infrastructure, relationships and credibility take decades to build. That's a moat VCs can't buy quickly.
Sometimes the best businesses are built in markets too boring for most people to care about.
Financing highways is definitely boring enough.
Wanna invest in a Nigeria dam?
Under the hood
When you're handed a pile of infrastructure fundraising documents — half-scanned PDFs, pitch decks, financial models — and told to "make it AI-ready," you quickly realize there's no standard. Not in format, not in naming, not in logic. Every file is its own taxonomic disaster.
One project calls it IRR_final_v2_FINAL.xlsx. Another buries the same info on page 154 of a feasibility study. In Comic Sans. (Not really.)
We're talking about documents that make healthcare billing look organized. So we built an agentic pipeline that doesn't care. Dump in feasibility reports, financial projections, municipal approvals, whatever — our system ingests, validates, enriches, and spits out a standardized, investor-ready tear sheet in 7 minutes.
The pipeline
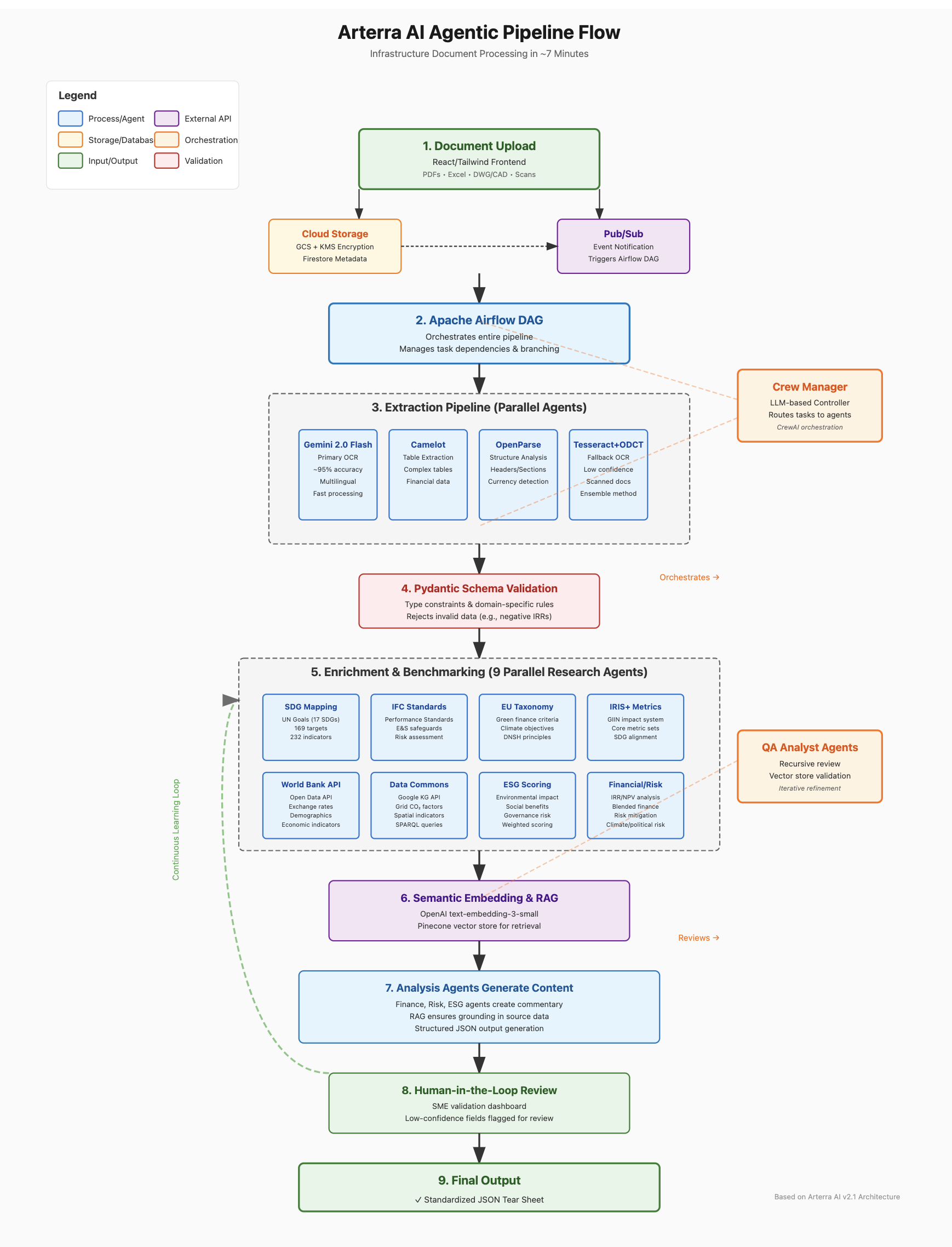
1. Ingestion & storage. Files hit our React/Tailwind frontend and flow into GCP Cloud Storage, encrypted with per-object KMS keys. Metadata gets hashed and indexed in Firestore. That kicks off our Apache Airflow DAG — the pipeline conductor. Yes, we used Airflow. No, we don't want to talk about the YAML configs.
2. Extraction.
- OCR: Gemini Flash as primary (fast and cheap), Tesseract & local OCR ensemble as backup for when someone scans a document on their 2003 Canon
- Tables: Camelot for clean docs, custom heuristics for messy ones
- Narrative structure: OpenParse (when it works)
Our initial OCR pipeline choked hard on multilingual PDFs and inconsistent formatting. Spanish scans turned into Quenya. Portuguese became Klingon. Took us two weeks, a layered fallback with Tesseract, and enough pre-processing to recede a data engineer's hairline to fix it.
All raw data gets beaten into submission by Pydantic schemas. No megawatts of hospital capacity. No negative IRRs (unless you're doing social infrastructure, where losing money is apparently the point).
3. Enrichment. Once extracted, project data gets enriched by a swarm of Research Agents:
- Mapped to SDGs, IFC Performance Standards, EU Taxonomy, GIIN IRIS+
- Benchmarked against World Bank Open Data (when their API works) and Data Commons API
- Every metric tagged with source, timestamp, and a prayer that it's accurate
4. Embeddings + RAG. The part where we pretend we're doing cutting-edge AI™:
- Vectorized via
text-embedding-3-small - Stored in Pinecone because who would've thought clear docs is a competitive advantage
- Used only for generating commentary, not numeric fields (because letting LLMs generate numbers is like letting your nephew do your taxes)
- All AI-generated commentary grounded in source data via retrieval
5. Human-in-the-loop.
- Low-confidence fields flagged in reviewer dashboard
- SMEs approve, correct, or reject
- All edits logged and pushed back into the training loop to enable AI network effects
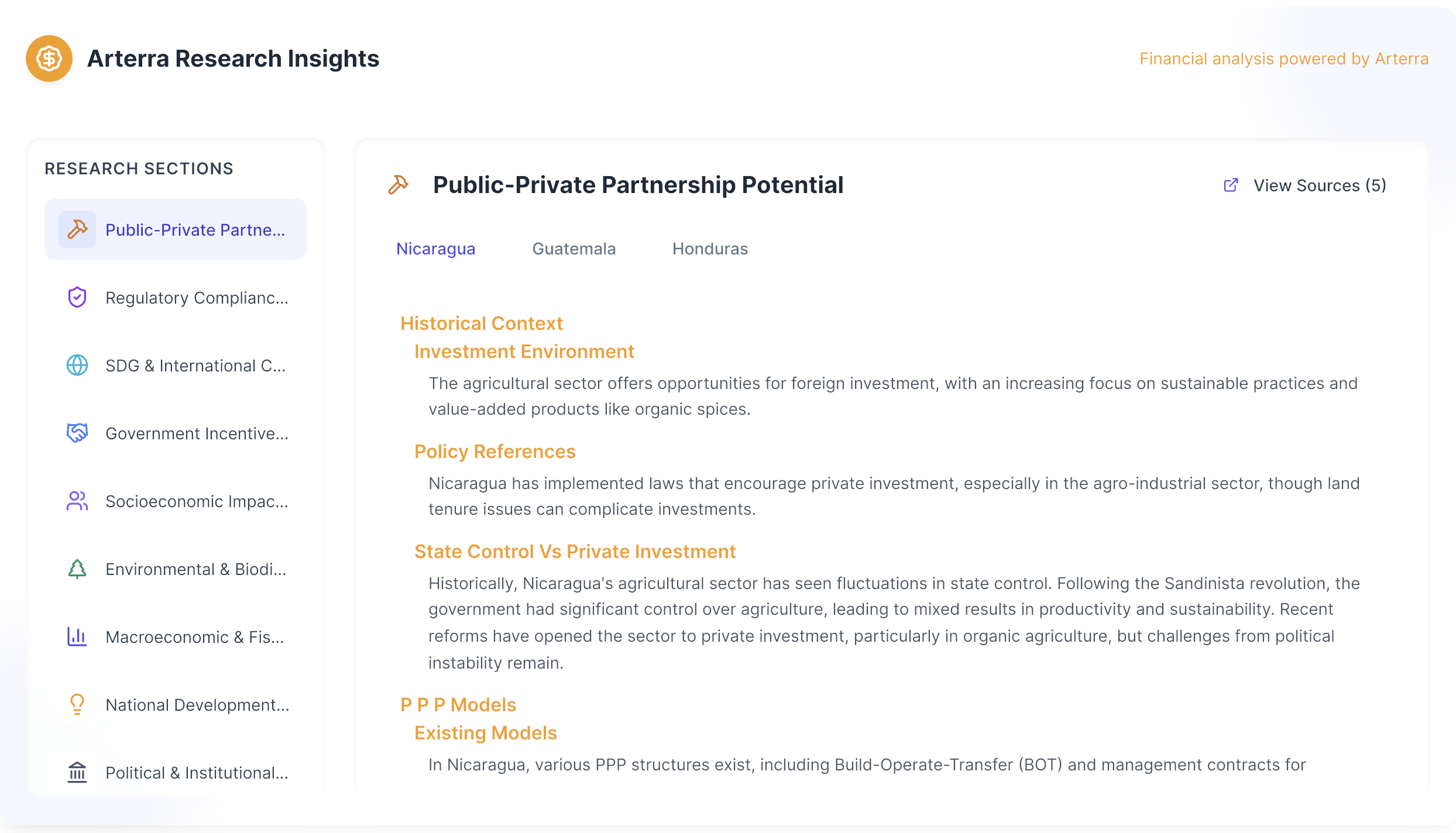
SME benchmarking protocol
| Section | SME quantitative (% correct) | SME qualitative |
|---|---|---|
| alignments.json | 95% | High |
| arterraResearchInsights.json | 90% | Medium — strong, but minor context gaps |
| developmentImpact.json | 93% | High |
| executiveOverview.json | 92% | High |
| financialDashboard.json | 94% | High |
| heroData.json | 91% | Medium |
| impactSustainability.json | 90% | Medium |
| marketDemandCompetitor.json | 89% | Medium — needs fresher benchmarks |
| ownershipStakeholders.json | 96% | High |
| projectOwnerDetails.json | 93% | High |
| riskAnalysisMitigation.json | 92% | High |
| SDG.json | 92% | High |
| technicalOperationalOverview.json | 91% | High — minor formatting issues |
| timelineMilestones.json | 94% | High |
| Overall weighted average | ≈ 92.5% | High |
6. Clean room sharing. Because folks in this line of work got more trust issues than my ex:
- Secure, zero-trust data rooms on Cloud Run
- Per-user, per-doc access control
- Project owners choose when to share
The architecture
| Layer | Tech | Why |
|---|---|---|
| Frontend | React + Tailwind | Fast to ship and doesn't look like it was built by the DMV |
| Backend | Node.js on Cloud Run | Containerized, scales, and costs basically nothing |
| Storage | GCS + Firestore | Encrypted by default, queryable, and Google's problem if it goes down |
| Orchestration | Airflow + Pub/Sub | Clean DAGs for the data pipeline nerds, async for everything else |
| Agent Runtime | CrewAI | LangChain made us want to commit seppuku |
Agents run in parallel. Local validation catches 80% of issues before things get expensive. QA agents recheck against vector stores. And the feedback loop actually works (again, cutting-edge AI™) — we watched accuracy climb from 75% to 92.5% over 50 iterations.
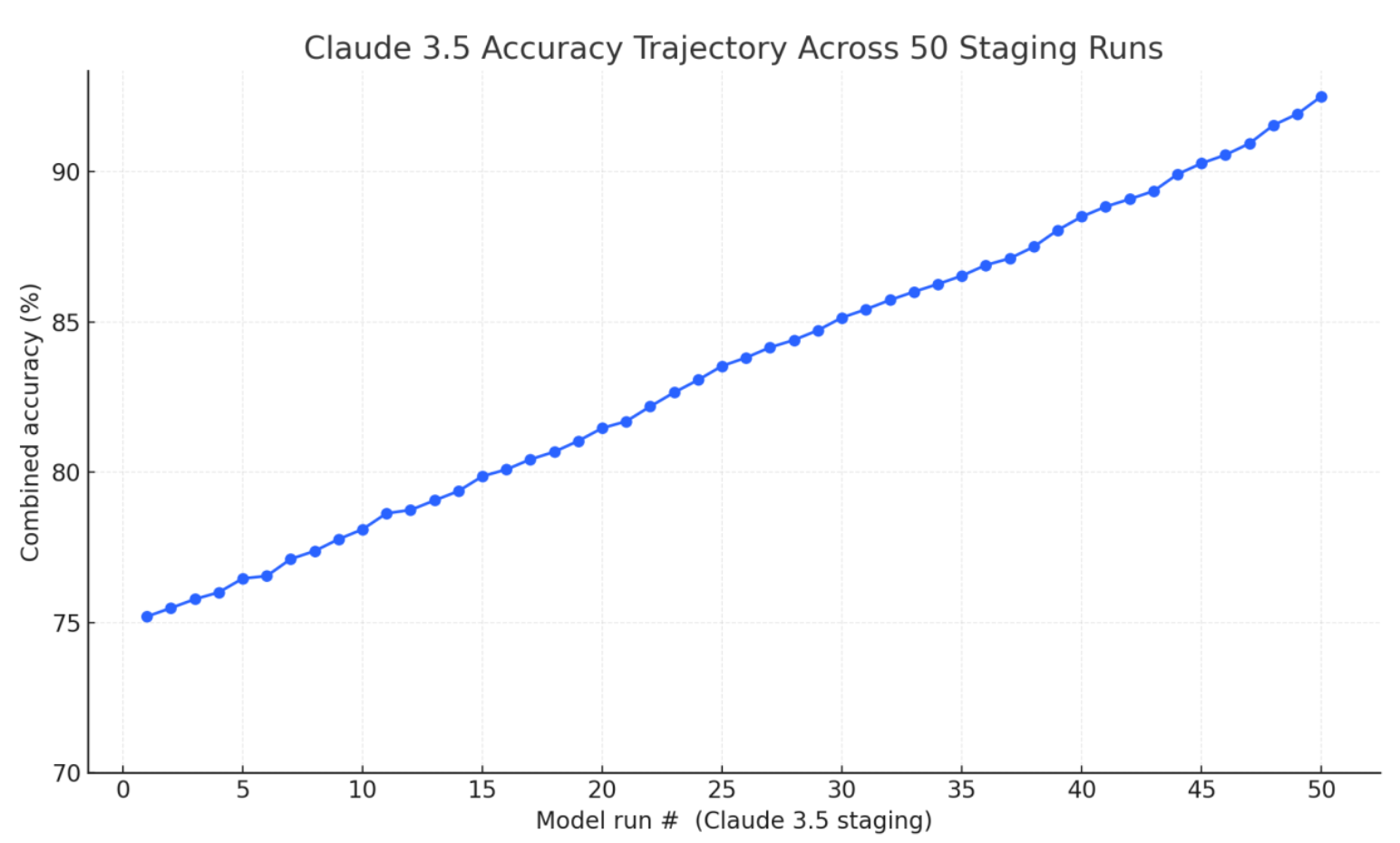
What worked
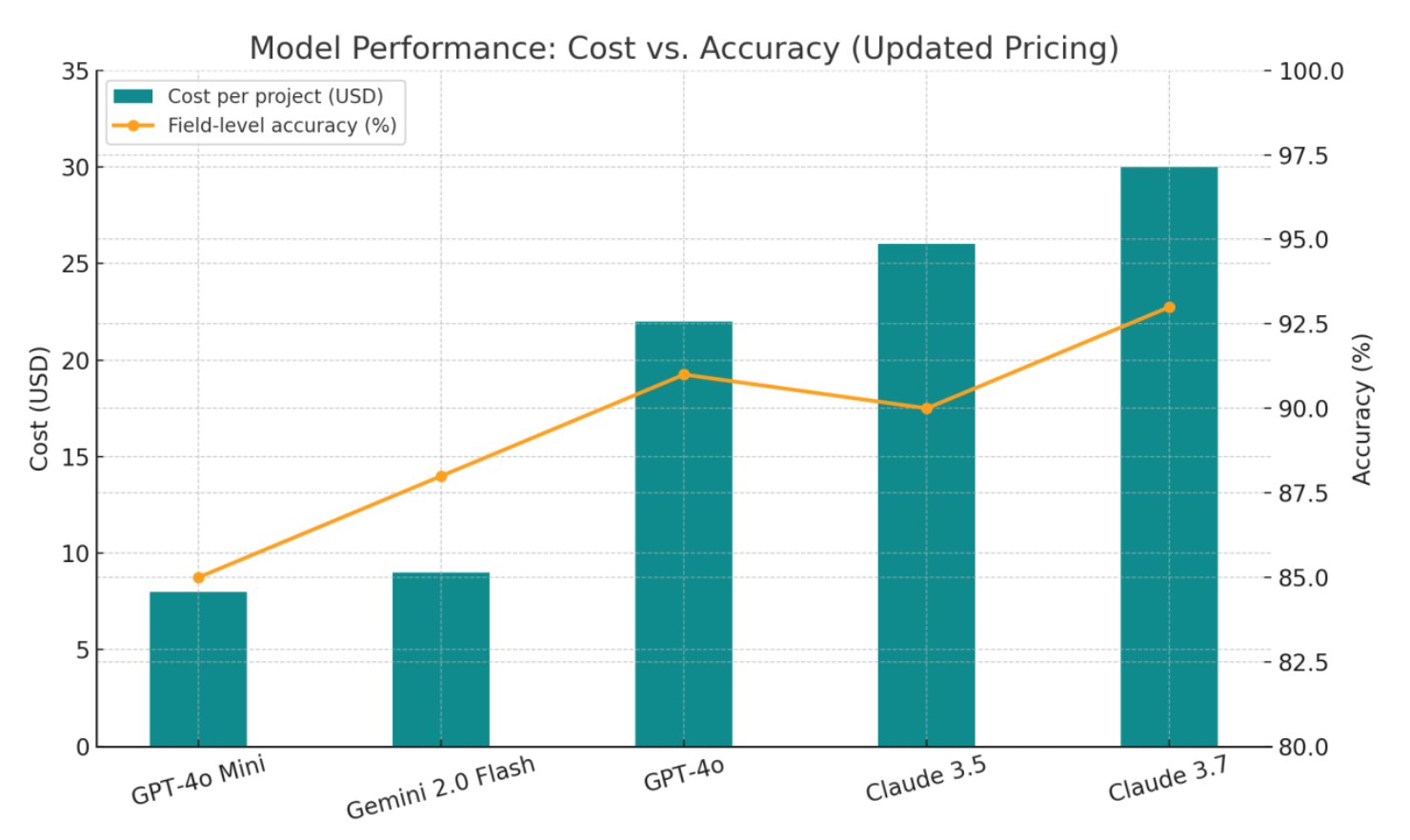
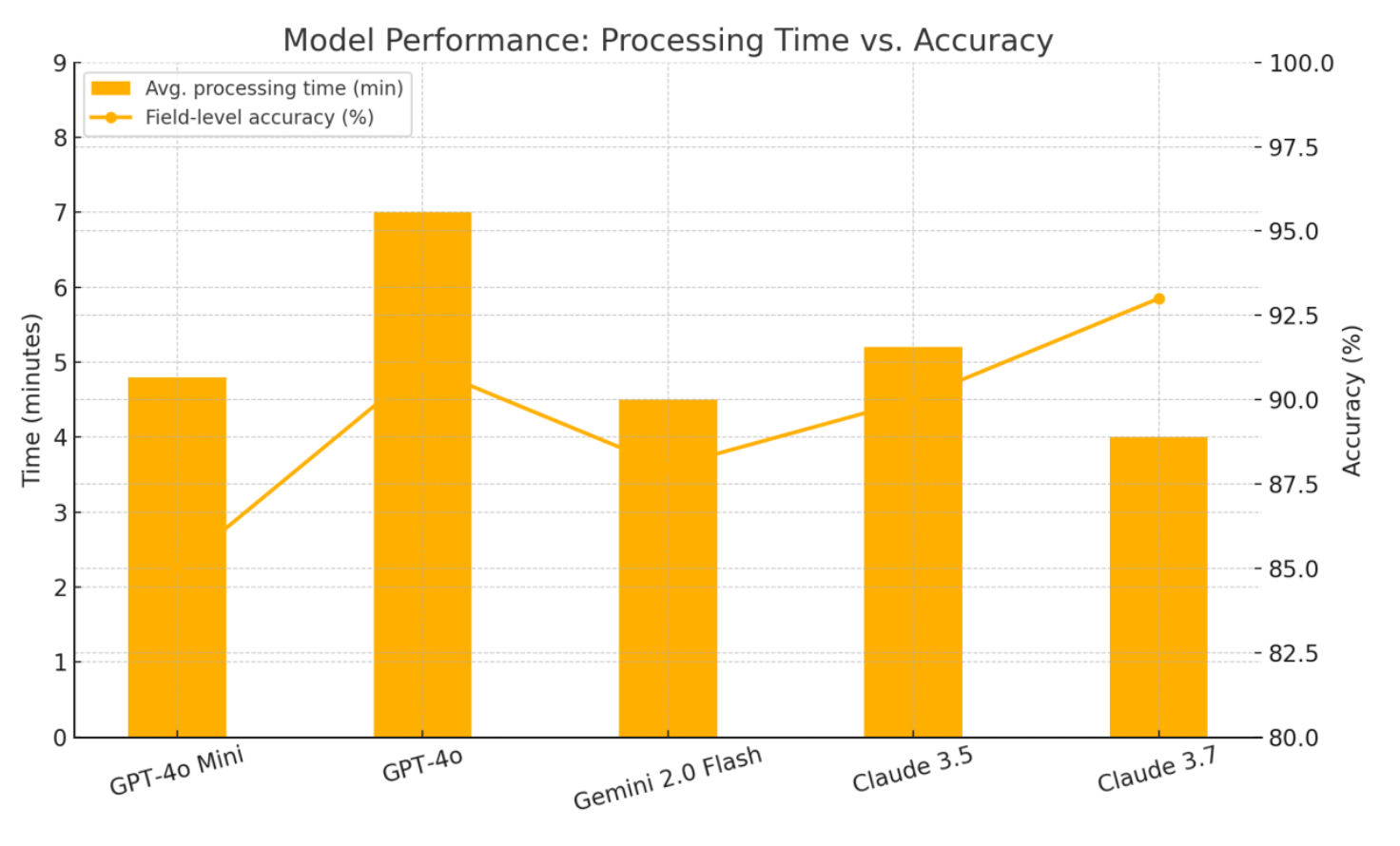
- Gemini 2.0 Flash. Best tradeoff between speed, cost, and accuracy.
- Strict schema validation. Saved us from untraceable bugs and existential dread.
- Agent call limits. Accuracy plateaued after 50 calls, so we capped it to keep latency low and our AWS bill from requiring a Series A.
- SME feedback loop. Real feedback, real learning, and gives us a moat (though a pretty shallow one) by enabling AI network effects.
What we learned
- Start with schemas, not models. Models are replaceable. Structure is strategy.
- If it can't be audited, it won't be trusted. Especially when public money is on the line.
- Human-in-the-loop isn't a compromise. It's a trust multiplier.
- Build for the worst case. Because real life sucks.